As I move through my 20's I'm consistently delighted by the subtle ways in which I've changed.
Will at 22: Reggaeton is a miserable, criminal assault to my ears.
Will at 28: Despacito (Remix) for breakfast, lunch, dinner.
Will at 22: Western Europe is boring. No — I've seen a lot of it! Everything is too clean, too nice, too perfect for my taste.
Will at 28, in Barcelona, after 9 months in Casablanca: Wait a second: I get it now. What is this summertime paradise of crosswalks, vehicle civility and apple-green parks and where has it been all my life?
Will at 22: Emojis are weird.
Will at 28: 🚀 🤘 💃🏿 🚴🏻 🙃.
Emojis are an increasingly-pervasive sub-lingua-franca of the internet. They capture meaning in a rich, concise manner — alternative to the 13 seconds of mobile thumb-fumbling required to capture the same meaning with text. Furthermore, they bring two levels of semantic information: their context within raw text and the pixels of the emoji itself.
Question-answer models
The original aim of this post was to explore Siamese question-answer models of the type typically applied to the InsuranceQA Corpus as introduced in "Applying Deep Learning To Answer Selection: A Study And An Open Task" (Feng, Xiang, Glass, Wang, & Zhou, 2015). We'll call them SQAM for clarity. The basic architecture looks as follows:
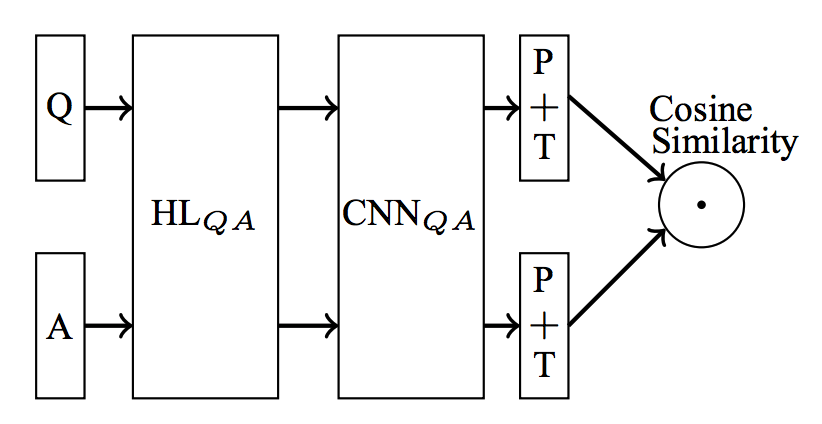
By layer and in general terms:
- An input — typically a sequence of token ids — for both question (Q) and answer (A).
- An embedding layer.
- Convolutional layer(s), or any layers that extract features from the matrix of embeddings. (A matrix, because the respective inputs are sequences of token ids; each id is embedded into its own vector.)
- A max-pooling layer.
- A
tanhnon-linearity. - The cosine of the angle between the resulting, respective embeddings.
As canonical recommendation
Question answering can be viewed as canonical recommendation: embed entities into Euclidean space in a meaningful way, then compute dot products between these entities and sort the list. In this vein, the above network is (thus far) quite similar to classic matrix factorization yet with the following subtle tweaks:
- Instead of factorizing our matrix via SVD or OLS we build a neural network that accepts
(question, answer), i.e.(user, item), pairs and outputs their similarity. The second-to-last layer gives the respective embeddings. We train this network in a supervised fashion, optimizing its parameters via stochastic gradient descent. - Instead of jumping directly from input-index (or sequence thereof) to embedding, we first compute convolutional features.
In contrast, the network above boasts one key difference: both question and answer, i.e. user and item, are transformed via a single set of parameters — an initial embedding layer, then convolutional layers — en route to their final embedding.
Furthermore, and not unique to SQAMs, our network inputs can be any two sequences of (tokenized, max-padded, etc.) text: we are not restricted to only those observed in the training set.
Question-emoji models
Given my accelerating proclivity for the internet's new alphabet, I decided to build text-question-emoji-answer models instead. In fact, this setup gives an additional avenue for prediction: if we make a model of the answers (emojis) themselves, we can now predict on, i.e. compute similarity with, each of
- Emojis we saw in the training set.
- New emojis, i.e. either not in the training set or new (like, released months from now) altogether.
- Novel emojis generated from the model of our data. In this way, we could conceivably answer a question with: "we suggest this new emoji we've algorithmically created ourselves that no one's ever seen before."
Let's get started.
Convolutional variational autoencoders
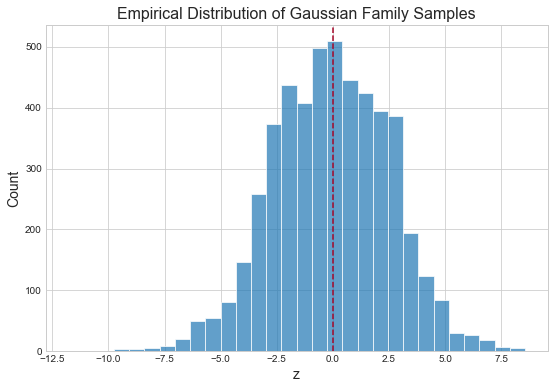
Variational autoencoders are comprised of two models: an encoder and a decoder. The encoder embeds our 872 emojis of size \((36, 36, 4)\) into a low-dimensional latent code, \(z_e \in \mathbb{R}^{16}\), where \(z_e\) is a sample from an emoji-specific Gaussian. The decoder takes as input \(z_e\) and produces a reconstruction of the original emoji. As each individual \(z_e\) is normally distributed, \(z\) should be distributed normally as well. We can verify this with a quick simulation.
mu = np.linspace(-3, 3, 10)
sd = np.linspace(0, 3, 10)
z_samples = []
for m in mu:
for s in sd:
samples = np.random.normal(loc=m, scale=s, size=50)
z_samples.append( samples )
z_samples = np.array(z_samples).ravel()
Training a variational autoencoder to learn low-dimensional emoji embeddings serves two principal ends:
- We can feed these low-dimensional embeddings as input to our SQAM.
- We can generate novel emojis with which to answer questions.
As the embeddings in #1 are multivariate Gaussian, we can perform #2 by passing Gaussian samples into our decoder. We can do this by sampling evenly-spaced percentiles from the inverse CDF of the aggregate embedding distribution:
percentiles = np.linspace(0, 1, 20)
for p in percentiles:
z = norm.ppf(p, size=16)
generated_emoji = decoder.predict([z])
NB: norm.ppf does not accept a size parameter; I believe sampling from the inverse CDF of a multivariate Gaussian is non-trivial in Python.
Similarly, we could simply iterate over (mu, sd) pairs outright:
axis = np.linspace(-3, 3, 20)
for mu in axis:
for sd in axis:
z = norm.rvs(loc=mu, scale=sd, size=16)
generated_emoji = decoder.predict([z])
The ability to generate new emojis via samples from a well-studied distribution, the Gaussian, is a key reason for choosing a variational autoencoder.
Finally, as we are working with images, I employ convolutional intermediary layers.
Data preparation
EMOJIS_DIR = 'data/emojis'
N_CHANNELS = 4
EMOJI_SHAPE = (36, 36, N_CHANNELS)
emojis_dict = {}
for slug in os.listdir(EMOJIS_DIR):
path = os.path.join(EMOJIS_DIR, slug)
emoji = imread(path)
if emoji.shape == (36, 36, 4):
emojis_dict[slug] = emoji
emojis = np.array( list(emojis_dict.values()) )
Split data into train, validation sets
Additionally, scale pixel values to \([0, 1]\).
train_mask = np.random.rand( len(emojis) ) < 0.8
X_train = y_train = emojis[train_mask] / 255.
X_val = y_val = emojis[~train_mask] / 255.
Dataset sizes:
X_train: (685, 36, 36, 4)
X_val: (182, 36, 36, 4)
y_train: (685, 36, 36, 4)
y_val: (182, 36, 36, 4)
Before we begin, let's examine some emojis.

Model emojis
EMBEDDING_SIZE = 16
FILTER_SIZE = 64
BATCH_SIZE = 16
Variational layer
This is taken from a previous post of mine, Transfer Learning for Flight Delay Prediction via Variational Autoencoders.
class VariationalLayer(KerasLayer):
def __init__(self, embedding_dim: int, epsilon_std=1.):
'''A custom "variational" Keras layer that completes the
variational autoencoder.
Args:
embedding_dim : The desired number of latent dimensions in our
embedding space.
'''
self.embedding_dim = embedding_dim
self.epsilon_std = epsilon_std
super().__init__()
def build(self, input_shape):
self.z_mean_weights = self.add_weight(
shape=input_shape[-1:] + (self.embedding_dim,),
initializer='glorot_normal',
trainable=True,
name='z_mean_weights'
)
self.z_mean_bias = self.add_weight(
shape=(self.embedding_dim,),
initializer='zero',
trainable=True,
name='z_mean_bias'
)
self.z_log_var_weights = self.add_weight(
shape=input_shape[-1:] + (self.embedding_dim,),
initializer='glorot_normal',
trainable=True,
name='z_log_var_weights'
)
self.z_log_var_bias = self.add_weight(
shape=(self.embedding_dim,),
initializer='zero',
trainable=True,
name='z_log_var_bias'
)
super().build(input_shape)
def call(self, x):
z_mean = K.dot(x, self.z_mean_weights) + self.z_mean_bias
z_log_var = K.dot(x, self.z_log_var_weights) + self.z_log_var_bias
epsilon = K.random_normal(
shape=K.shape(z_log_var),
mean=0.,
stddev=self.epsilon_std
)
kl_loss_numerator = 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var)
self.kl_loss = -0.5 * K.sum(kl_loss_numerator, axis=-1)
return z_mean + K.exp(z_log_var / 2) * epsilon
def loss(self, x, x_decoded):
base_loss = binary_crossentropy(x, x_decoded)
base_loss = tf.reduce_sum(base_loss, axis=[-1, -2])
return base_loss + self.kl_loss
def compute_output_shape(self, input_shape):
return input_shape[:1] + (self.embedding_dim,)
Autoencoder
# encoder
original = Input(shape=EMOJI_SHAPE, name='original')
conv = Conv2D(filters=FILTER_SIZE, kernel_size=3, input_shape=original.shape, padding='same', activation='relu')(original)
conv = Conv2D(filters=FILTER_SIZE, kernel_size=3, padding='same', activation='relu')(conv)
conv = Conv2D(filters=FILTER_SIZE, kernel_size=3, padding='same', activation='relu')(conv)
flat = Flatten()(conv)
variational_layer = VariationalLayer(EMBEDDING_SIZE)
variational_params = variational_layer(flat)
encoder = Model([original], [variational_params], name='encoder')
# decoder
encoded = Input(shape=(EMBEDDING_SIZE,))
upsample = Dense(np.multiply.reduce(EMOJI_SHAPE), activation='relu')(encoded)
reshape = Reshape(EMOJI_SHAPE)(upsample)
deconv = Conv2DTranspose(filters=FILTER_SIZE, kernel_size=3, padding='same', activation='relu', input_shape=encoded.shape)(reshape)
deconv = Conv2DTranspose(filters=FILTER_SIZE, kernel_size=3, padding='same', activation='relu')(deconv)
deconv = Conv2DTranspose(filters=FILTER_SIZE, kernel_size=3, padding='same', activation='relu')(deconv)
dropout = Dropout(.8)(deconv)
reconstructed = Conv2DTranspose(filters=N_CHANNELS, kernel_size=3, padding='same', activation='sigmoid')(dropout)
decoder = Model([encoded], [reconstructed], name='decoder')
# end-to-end
encoder_decoder = Model([original], decoder(encoder([original])))
The full model encoder_decoder is composed of separate models encoder and decoder. Training the former will implicitly train the latter two; they are available for our use thereafter.
The above architecture takes inspiration from Keras, Edward and the GDGS (gradient descent by grad student) method by as discussed by Brudaks on Reddit:
A popular method for designing deep learning architectures is GDGS (gradient descent by grad student). This is an iterative approach, where you start with a straightforward baseline architecture (or possibly an earlier SOTA), measure its effectiveness; apply various modifications (e.g. add a highway connection here or there), see what works and what does not (i.e. where the gradient is pointing) and iterate further on from there in that direction until you reach a (local?) optimum.
I'm not a grad student but I think it still plays.
Fit model
encoder_decoder.compile(optimizer=Adam(.003), loss=variational_layer.loss)
encoder_decoder_fit = encoder_decoder.fit(
x=X_train,
y=y_train,
batch_size=16,
epochs=100,
validation_data=(X_val, y_val)
)
Generate emojis
As promised we'll generate emojis. Again, latent codes are distributed as a (16-dimensional) Gaussian; to generate, we'll simply take samples thereof and feed them to our decoder.
While scanning a 16-dimensional hypercube, i.e. taking (evenly-spaced, usually) samples from our latent space, is a few lines of Numpy, visualizing a 16-dimensional grid is impractical. In solution, we'll work on a 2-dimensional grid while treating subsets of our latent space as homogenous.
For example, if our 2-D sample were (0, 1), we could posit 16-D samples as:
A. `(0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1)`
B. `(0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1)`
C. `(0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1)`
Then, if another sample were (2, 3.5), we could posit 16-D samples as:
A. `(2, 2, 2, 2, 2, 2, 2, 2, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5)`
B. `(2, 3.5, 2, 3.5, 2, 3.5, 2, 3.5, 2, 3.5, 2, 3.5, 2, 3.5, 2, 3.5)`
C. `(2, 2, 3.5, 3.5, 2, 2, 3.5, 3.5, 2, 2, 3.5, 3.5, 2, 2, 3.5, 3.5)`
There is no math here: I'm just creating 16-element lists in different ways. We'll then plot "A-lists," "B-lists," etc. separately.
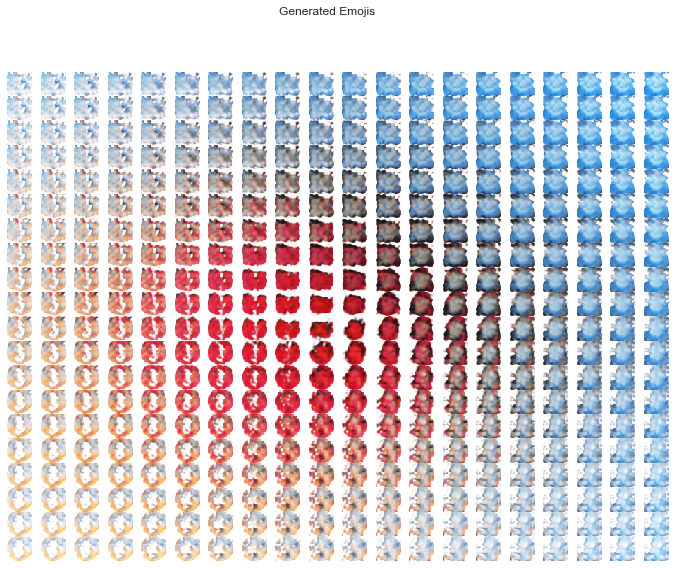
def compose_code_A(coord_1, coord_2):
return 8 * [coord_1] + 8 * [coord_2]
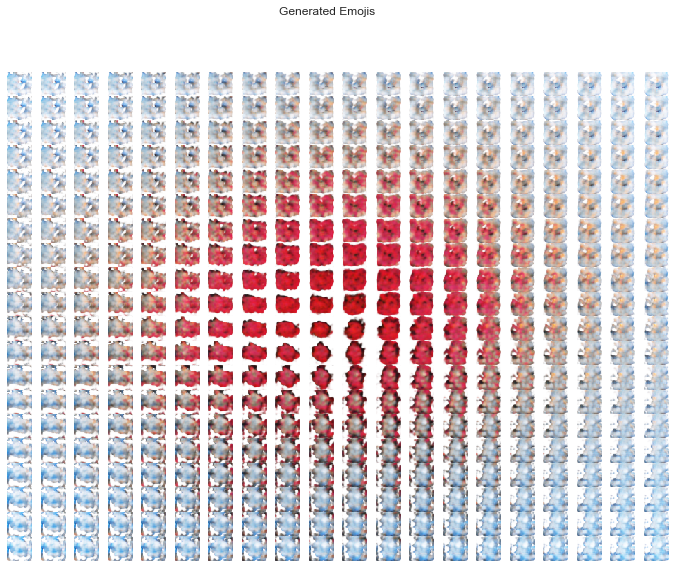
def compose_code_B(coord_1, coord_2):
return 8 * [coord_1, coord_2]
def compose_code_C(coord_1, coord_2):
return 4 * [coord_1, coord_1, coord_2, coord_2]
ticks = 20
axis = np.linspace(-2, 2, ticks)
plot_generated_emojis(compose_code_A)
plot_generated_emojis(compose_code_B)
plot_generated_emojis(compose_code_C)
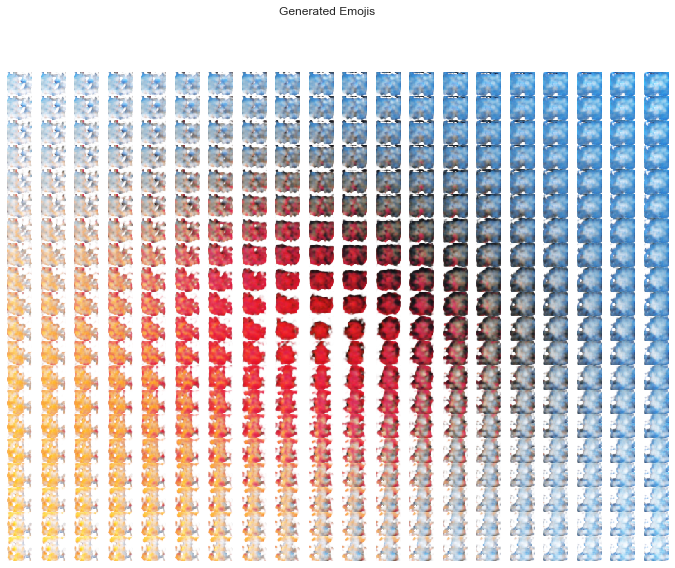
As our emojis live in a continuous latent space we can observe the smoothness of the transition from one to the next.
The generated emojis have the makings of maybe some devils, maybe some bubbles, maybe some hearts, maybe some fish. I doubt they'll be featured on your cell phone's keyboard anytime soon.
Text-question, emoji-answer
I spent a while looking for an adequate dataset to no avail. (Most Twitter datasets are not open-source, I requested my own tweets days ago and continue to wait, etc.) As such, I'm working with the Twitter US Airline Sentiment dataset: tweets are labeled as positive, neutral, negative which I've mapped to 🎉, 😈 and 😡.
Contrastive loss
We've thus far discussed the SQAM. Our final model will make use of two SQAM's in parallel, as follows:
- Receive
(question, correct_answer, incorrect_answer)triplets as input. - Compute the cosine similarity between
question,correct_answerviaSQAM_1—correct_cos_sim. - Compute the cosine similarity between
question,incorrect_answerviaSQAM_2—incorrect_cos_sim.
The model is trained to minimize the following: max(0, margin - correct_cos_sim + incorrect_cos_sim), a variant of the hinge loss. This ensures that (question, correct_answer) pairs have a higher cosine similarity than (question, incorrect_answer) pairs, mediated by margin. Note that this function is differentiable: it is simply a ReLU.
Architecture
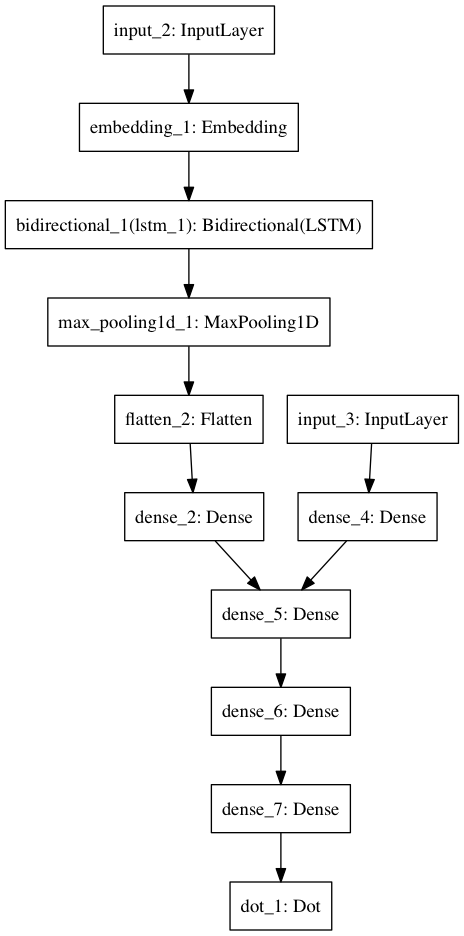
A single SQAM receives two inputs: a question — a max-padded sequence of token ids — and an answer — an emoji's 16-D latent code.
To process the question we employ the following steps, i.e. network layers:
- Select the pre-trained-with-Glove 100-D embedding for each token id. This gives a matrix of size
(MAX_QUESTION_LEN, GLOVE_EMBEDDING_DIM). -
Pass the result through a bidirectional LSTM — (apparently) key to current state-of-the-art results in a variety of NLP tasks. This can be broken down as follows:
- Initialize two matrices of size
(MAX_QUESTION_LEN, LSTM_HIDDEN_STATE_SIZE):forward_matrixandbackward_matrix. - Pass the sequence of token ids through an LSTM and return all hidden states. The first hidden state is a function of, i.e. is computed using, the first token id's embedding; place it in the first row of
forward_matrix. The second hidden state is a function of the first and second token-id embeddings; place it in the second row offorward_matrix. The third hidden state is a function of the first and second and third token-id embeddings, and so forth. - Do the same thing but pass the sequence to the LSTM in reverse order. Place the first hidden state in the last row of
backward_matrix, the second hidden state in the second-to-last row ofbackward_matrix, etc. - Concatenate
forward_matrixandbackward_matrixinto a single matrix of size(MAX_QUESTION_LEN, 2 * LSTM_HIDDEN_STATE_SIZE).
- Initialize two matrices of size
- Flatten.
- Dense layer with ReLU activations, down to 10 dimensions.
To process the answer we employ the following steps:
- Dense layer with ReLU activations.
- Dense layer with ReLU activations, down to 10 dimensions.
Now of equal size, we further process our question and answer with a single set of dense layers — the key difference between a SQAM and (the neural-network formulation of) other canonical (user, item) recommendation algorithms. The last of these layers employs tanh activations as suggested in Feng et al. (2015).
Finally, we compute the cosine similarity between the resulting embeddings.
Prepare questions, answers
Import tweets
tweets_df = pd.read_csv('data/tweets.csv')[['text', 'airline_sentiment']]\
.sample(5000)\
.reset_index()
tweets_df.head()
| index | text | airline_sentiment | |
|---|---|---|---|
| 0 | 2076 | @united that's not an apology. Say it. | negative |
| 1 | 7534 | @JetBlue letting me down in San Fran. No Media... | negative |
| 2 | 14441 | @AmericanAir where do I look for cabin crew va... | neutral |
| 3 | 13130 | @AmericanAir just sad that even after spending... | negative |
| 4 | 3764 | @united What's up with the reduction in E+ on ... | negative |
Embed answers into 16-D latent space
Additionally, scale the latent codes; these will be fed to our network as input.
# embed
sentiment_embeddings = np.array([emojis_dict['1f389.png'], emojis_dict['1f608.png'], emojis_dict['1f621.png']])
sentiment_embeddings = encoder.predict(sentiment_embeddings).astype(np.float64)
# scale
sentiment_embeddings = scale(sentiment_embeddings)
# build vectors of correct, incorrect answers
embedding_map = {
'positive': sentiment_embeddings[0], 'neutral': sentiment_embeddings[1], 'negative': sentiment_embeddings[2]
}
incorrect_answers, correct_answers = [], []
sentiments = set( embedding_map.keys() )
for sentiment in tweets_df['airline_sentiment']:
correct_answers.append( embedding_map[sentiment] )
incorrect_sentiment = random.sample(sentiments - {sentiment}, 1)[0]
incorrect_answers.append( embedding_map[incorrect_sentiment] )
questions = tweets_df['text']
correct_answers = np.array(correct_answers)
incorrect_answers = np.array(incorrect_answers)
We've now built (only) one (question, correct_answer, incorrect_answer) training triplet for each ground-truth (question, correct_answer). In practice, we should likely have many more, i.e. (question, correct_answer, incorrect_answer_1), (question, correct_answer, incorrect_answer_2), ..., (question, correct_answer, incorrect_answer_n).
Construct sequences of token ids
MAX_QUESTION_LEN = 20
VOCAB_SIZE = 2000
tokenizer = Tokenizer(num_words=VOCAB_SIZE)
tokenizer.fit_on_texts(questions)
question_seqs = tokenizer.texts_to_sequences(questions)
question_seqs = pad_sequences(question_seqs, maxlen=MAX_QUESTION_LEN)
Split data into train, validation sets
NB: We don't actually have y values: we pass (question, correct_answer, incorrect_answer) triplets to our network and try to minimize max(0, margin - correct_cos_sim + incorrect_cos_sim). Notwithstanding, Keras requires that we pass both x and y (as Numpy arrays); we pass the latter as a vector of 0's.
train_mask = np.random.rand( len(question_seqs) ) < 0.8
questions_train = question_seqs[train_mask]
correct_answers_train = correct_answers[train_mask]
incorrect_answers_train = incorrect_answers[train_mask]
questions_val = question_seqs[~train_mask]
correct_answers_val = correct_answers[~train_mask]
incorrect_answers_val = incorrect_answers[~train_mask]
y_train_dummy = np.zeros(shape=questions_train.shape[0])
y_val_dummy = np.zeros(shape=questions_val.shape[0])
Dataset sizes:
questions_train: (4079, 20)
correct_answers_train: (4079, 16)
incorrect_answers_train: (4079, 16)
questions_val: (921, 20)
correct_answers_val: (921, 16)
incorrect_answers_val: (921, 16)
Build embedding layer from Glove vectors
GLOVE_EMBEDDING_DIM = 100
# 1. Load Glove embeddings
# 2. Build embeddings matrix
# 3. Build Keras embedding layer
embedding_layer = Embedding(
input_dim=len(word_index) + 1,
output_dim=GLOVE_EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_QUESTION_LEN,
trainable=True
)
Build Siamese question-answer model (SQAM)
GDGS architecture, ✌️.
LSTM_HIDDEN_STATE_SIZE = 50
# question
question = Input(shape=(MAX_QUESTION_LEN,), dtype='int32')
question_embedding = embedding_layer(question)
biLSTM = Bidirectional(LSTM(LSTM_HIDDEN_STATE_SIZE, return_sequences=True))(question_embedding)
max_pool = MaxPool1D(10)(biLSTM)
flat = Flatten()(max_pool)
dense_question = Dense(10, activation='relu')(flat)
# answer
answer = Input(shape=(EMBEDDING_SIZE,))
dense_answer = Dense(64, activation='relu')(answer)
dense_answer = Dense(10, activation='relu')(answer)
# combine
shared_dense_1 = Dense(100, activation='relu')
shared_dense_2 = Dense(50, activation='relu')
shared_dense_3 = Dense(10, activation='tanh')
dense_answer = shared_dense_1(dense_answer)
dense_question = shared_dense_1(dense_question)
dense_answer = shared_dense_2(dense_answer)
dense_question = shared_dense_2(dense_question)
dense_answer = shared_dense_3(dense_answer)
dense_question = shared_dense_3(dense_question)
# compute cosine sim, a normalized dot product
cosine_sim = dot([dense_question, dense_answer], normalize=True, axes=-1)
# model
qa_model = Model([question, answer], [cosine_sim], name='qa_model')
Build contrastive model
Two Siamese networks, trained jointly so as to minimize the hinge loss of their respective outputs.
# contrastive model
correct_answer = Input(shape=(EMBEDDING_SIZE,))
incorrect_answer = Input(shape=(EMBEDDING_SIZE,))
correct_cos_sim = qa_model([question, correct_answer])
incorrect_cos_sim = qa_model([question, incorrect_answer])
def hinge_loss(cos_sims, margin=.2):
correct, incorrect = cos_sims
return K.relu(margin - correct + incorrect)
contrastive_loss = Lambda(hinge_loss)([correct_cos_sim, incorrect_cos_sim])
# model
contrastive_model = Model([question, correct_answer, incorrect_answer], [contrastive_loss], name='contrastive_model')
Build prediction model
This is what we'll use to compute the cosine similarity of novel (question, answer) pairs.
prediction_model = Model([question, answer], qa_model([question, answer]), name='prediction_model')
Fit contrastive model
Fitting contrastive_model will implicitly fit prediction_model as well, so long as the latter has been compiled.
# compile
optimizer = Adam(.001, clipnorm=1.)
contrastive_model.compile(loss=lambda y_true, y_pred: y_pred, optimizer=optimizer)
prediction_model.compile(loss=lambda y_true, y_pred: y_pred, optimizer=optimizer)
# fit
contrastive_model.fit(
x=[questions_train, correct_answers_train, incorrect_answers_train],
y=y_train_dummy,
batch_size=64,
epochs=3,
validation_data=([questions_val, correct_answers_val, incorrect_answers_val], y_val_dummy)
)
Train on 4089 samples, validate on 911 samples
Epoch 1/3
4089/4089 [==============================] - 18s - loss: 0.1069 - val_loss: 0.0929
Epoch 2/3
4089/4089 [==============================] - 14s - loss: 0.0796 - val_loss: 0.0822
Epoch 3/3
4089/4089 [==============================] - 14s - loss: 0.0675 - val_loss: 0.0828
Predict on new tweets
"@united Flight is awful only one lavatory functioning, and people lining up, bumping, etc. because can't use 1st class bathroom. Ridiculous"
"@usairways I've called for 3 days and can't get thru. is there some secret method i can use that doesn't result in you hanging up on me?"
"@AmericanAir Let's all have a extraordinary week and make it a year to remember #GoingForGreat 2015 thanks so much American Airlines!!!"
new_questions = [
"@united Flight is awful only one lavatory functioning, and people lining up, bumping, etc. because can't use 1st class bathroom. Ridiculous",
"@usairways I've called for 3 days and can't get thru. is there some secret method i can use that doesn't result in you hanging up on me?",
"@AmericanAir Let's all have a extraordinary week and make it a year to remember #GoingForGreat 2015 thanks so much American Airlines!!!"
]
new_questions_seq = tokenizer.texts_to_sequences(new_questions)
new_questions_seq = pad_sequences(new_questions_seq, maxlen=MAX_QUESTION_LEN)
n_questions, n_sentiments = len(new_questions_seq), len(sentiment_embeddings)
q = np.repeat(new_questions_seq, repeats=n_sentiments, axis=0)
a = np.tile(sentiment_embeddings, (n_questions, 1))
preds = prediction_model.predict([q, a])
Tweet #1
positive_pred, neutral_pred, negative_pred = preds[:3]
print('Predictions:')
print(f' 🎉 (Positive): {positive_pred[0]:0.5}')
print(f' 😈 (Neutral) : {neutral_pred[0]:0.5}')
print(f' 😡 (Negative): {negative_pred[0]:0.5}')
Predictions:
🎉 (Positive): 0.51141
😈 (Neutral) : 0.56273
😡 (Negative): 0.9728
Tweet #2
positive_pred, neutral_pred, negative_pred = preds[3:6]
print('Predictions:')
print(f' 🎉 (Positive): {positive_pred[0]:0.5}')
print(f' 😈 (Neutral) : {neutral_pred[0]:0.5}')
print(f' 😡 (Negative): {negative_pred[0]:0.5}')
Predictions:
🎉 (Positive): 0.41422
😈 (Neutral) : 0.61587
😡 (Negative): 0.99161
Tweet #3
positive_pred, neutral_pred, negative_pred = preds[6:9]
print('Predictions:')
print(f' 🎉 (Positive): {positive_pred[0]:0.5}')
print(f' 😈 (Neutral) : {neutral_pred[0]:0.5}')
print(f' 😡 (Negative): {negative_pred[0]:0.5}')
Predictions:
🎉 (Positive): 0.87107
😈 (Neutral) : 0.46741
😡 (Negative): 0.73435
Additionally, we can predict on the full set of emojis
Some emoji embeddings contain np.inf values, unfortunately. We could likely mitigate this by further tweaking the hyperparameters of our autoencoder.
all_embeddings = encoder.predict(emojis).astype(np.float64)
inf_mask = np.isinf(all_embeddings).any(axis=1)
print(f'{100 * inf_mask.mean():.3}% of values are `np.inf`.')
all_embeddings = all_embeddings[~inf_mask]
4.15% of values are `np.inf`.
n_questions, n_sentiments = len(new_questions_seq), len(all_embeddings)
q = np.repeat(new_questions_seq, repeats=n_sentiments, axis=0)
a = np.tile(all_embeddings, (n_questions, 1))
preds = prediction_model.predict([q, a])
Tweet #1
preds_1 = preds[:n_sentiments]
top_5_matches = extract_top_5_argmax(preds_1)
display_top_5_results(top_5_matches)

Tweet #2
preds_2 = preds[n_sentiments:2*n_sentiments]
top_5_matches = extract_top_5_argmax(preds_2)
display_top_5_results(top_5_matches)

Tweet #3
preds_3 = preds[2*n_sentiments:]
top_5_matches = extract_top_5_argmax(preds_3)
display_top_5_results(top_5_matches)

Not particularly useful. These emojis have 0 notion of sentiment, though: the model is simply predicting on their (pixel-based) latent codes.
Future work
In this work, we trained a convolutional variational autoencoder to model the distribution of emojis. Next, we trained a Siamese question-answer model to answer text questions with emoji answers. Finally, we were able to use the latter to predict on novel emojis from the former.
Moving forward, I see a few logical steps:
- Use emoji embeddings that are conscious of sentiment — likely trained via a different network altogether. This way, we could make more meaningful (sentiment-based) predictions on novel emojis.
- Predict on emojis generated from the autoencoder.
- Add 1-D convolutions to the text side of the SQAM.
- Add an "attention" mechanism — the one component missing from the "embed, encode, attend, predict" dynamic quartet of modern NLP.
- Improve the stability of our autoencoder so as to not produce embeddings containing
np.inf.
Sincere thanks for reading, and emojis 🤘.
Code
The repository and rendered notebook for this project can be found at their respective links.
References
- Deep Language Modeling for Question Answering using Keras
- Applying Deep Learning To Answer Selection: A Study And An Open Task
- LSTM Based Deep Learning Models For Non-Factoid Answer Selection
- Embed, encode, attend, predict: The new deep learning formula for state-of-the-art NLP models
- Keras Examples - Convolutional Variational Autoencoder
- Introducing Variational Autoencoders (in Prose and Code)
- Under the Hood of the Variational Autoencoder (in Prose and Code)