I recently finished building a web app that recommends travel destinations. You input a country, and it provides you with 5 other countries which you might also enjoy. The recommendations are generated via a basic application of collaborative filtering. In effect, you query for a country, and the engine suggests additional countries enjoyed by other users of similar taste. The methodology is pretty simple:
- Capture travel-related tweets from the Twitter API, defined as any containing the strings "#ttot", "#travel", "#lp", "vacation", "holiday", "wanderlust", "viajar", "voyager", "destination", "tbex", or "tourism."
- If a tweet contains the name of one of 248 countries or territories, or their respective capitals, label this tweet with this country. For example, the tweet "backpacking Iran is awesome! #travel" would be labled with "Iran."
- Represent each country as a set of the user_id's who have tweeted about it.
- Compute a Jaccard similarity - defined as the size of the intersection of 2 sets divided by the size of their union - between all combinations of countries.
- When a country is queried, return the 5 countries Jaccard-most similar. The length of the bars on the plot are the respective similarity scores. So - let's try a few out!
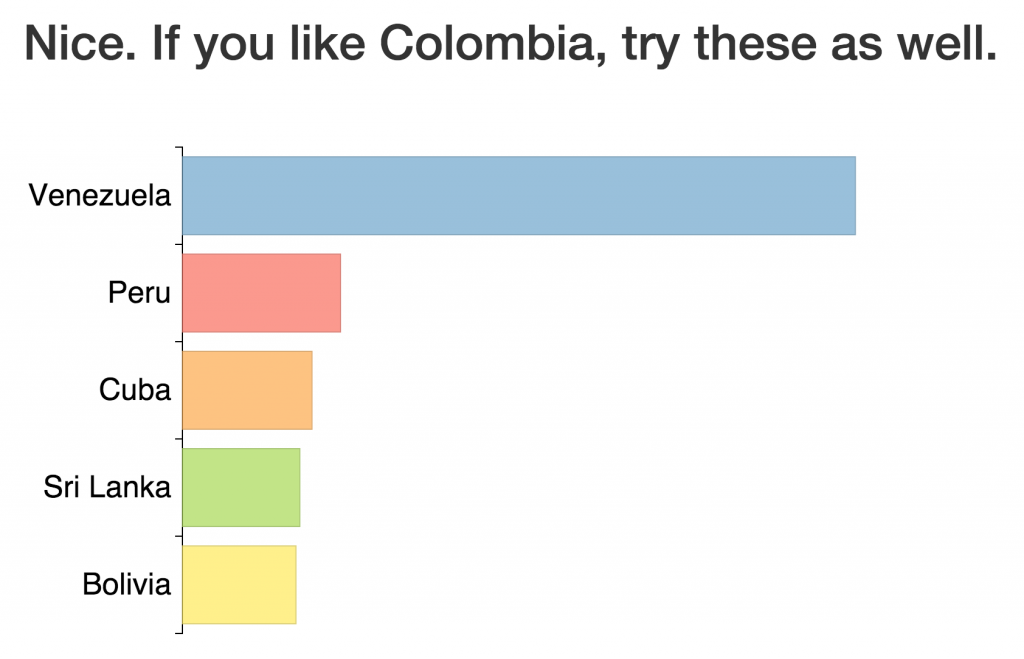
Not bad. Venezuela - neighbor to the East - is recommended most highly. Again, this implies that those tweeting about Colombia were also tweeting about Venezuela.
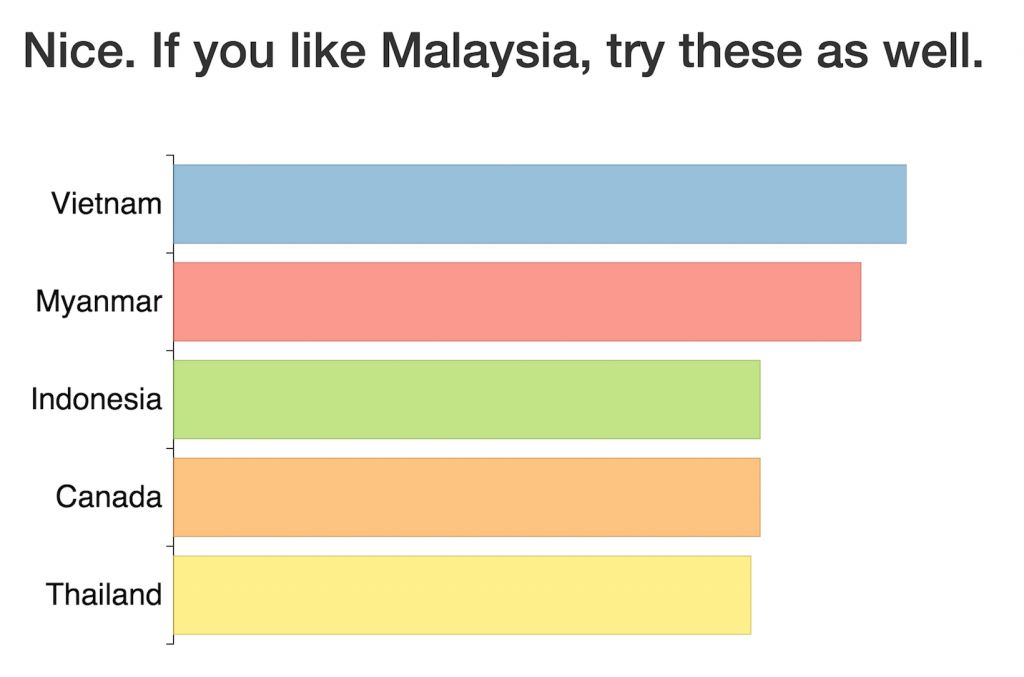
Seems logical.
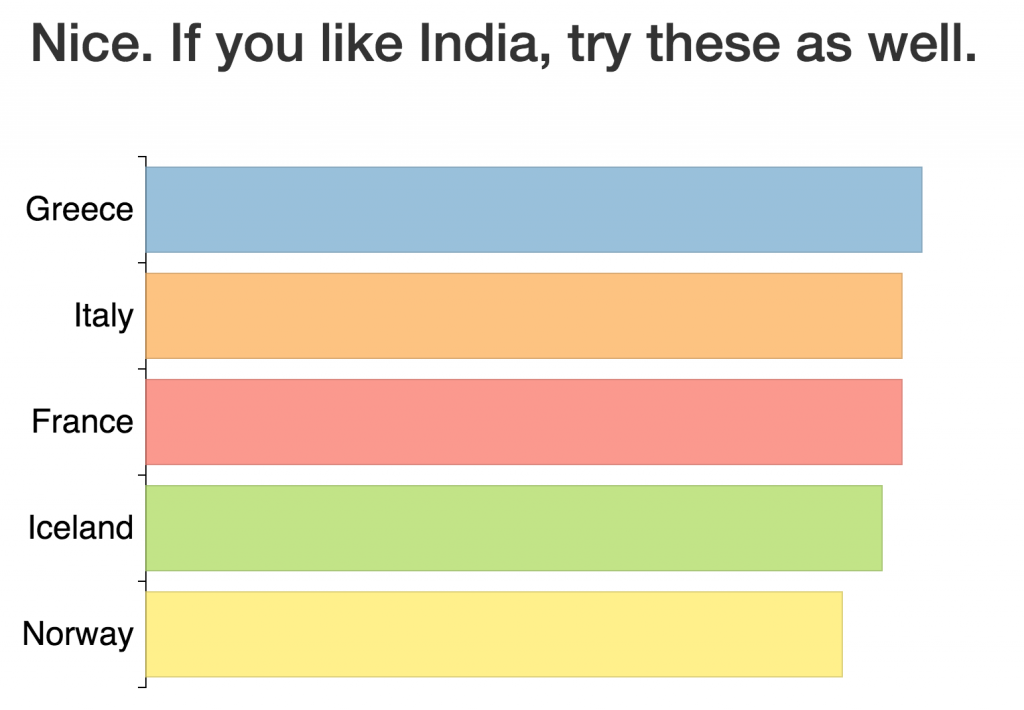
Strange one, maybe? Then again, all countries - especially Greece, Italy, and France - are universally popular travel destinations, just like our query country India. As such, it's certainly conceivable that they were being promoted by similar users. We'd want to read the tweets to be sure.
Moving forward, I plan to implement a more robust similarity metric/methodology. While a Jaccard similarity is effective, it's a little bit "bulky": most notably, being a set similarity metric, it doesn't consider repeat tweets about a given country. For example, if User A tweeted 12 times about Hungary and 1 time about Turkey, a Jaccard similarity would consider these behaviors equal (by simply including User A in each country's respective set). As such, a cosine-based metric might be more appropriate. See here for an excellent overview of possible approaches to a "people who like this also like" analysis.
Once more, the app is linked here. In addition, the code powering the app can be found on my GitHub. Backend in Scala, and front-end in HTML, CSS, and native JavaScript. Do take it for a spin, and let me know what you think!