Bayesian probabilistic models provide a nimble and expressive framework for modeling "small-world" data. In contrast, deep learning offers a more rigid yet much more powerful framework for modeling data of massive size. Edward is a probabilistic programming library that bridges this gap: "black-box" variational inference enables us to fit extremely flexible Bayesian models to large-scale data. Furthermore, these models themselves may take advantage of classic deep-learning architectures of arbitrary complexity.
Edward uses TensorFlow for symbolic gradients and data flow graphs. As such, it interfaces cleanly with other libraries that do the same, namely TF-Slim, PrettyTensor and Keras. Personally, I've been working often with the latter, and am consistently delighted by the ease with which it allows me to specify complex neural architectures.
The aim of this post is to lay a practical foundation for Bayesian modeling in Edward, then explore how, and how easily, we can extend these models in the direction of classical deep learning via Keras. It will give both a conceptual overview of the models below, as well as notes on the practical considerations of their implementation — what worked and what didn't. Finally, this post will conclude with concrete ways in which to extend these models further, of which there are many.
If you're just getting started with Edward or Keras, I recommend first perusing the Edward tutorials and Keras documentation respectively.
To "pull us down the path," we build three models in additive fashion: a Bayesian linear regression model, a Bayesian linear regression model with random effects, and a neural network with random effects. We fit them on the Zillow Prize dataset, which asks us to predict logerror (in house-price estimate, i.e. the "Zestimate") given metadata for a list of homes. These models are intended to be demonstrative, not performant: they will not win you the prize in their current form.
Data preparation
Build training DataFrame
data = transactions_df.merge(properties_df, how='left', left_on='id_parcel', right_on='id_parcel')
Drop columns containing too many nulls
Bayesian probabilistic models allow us to flexibly model missing data itself. To this end, we conceive of a given predictor as a vector of both:
- Observed values.
- Parameters in place of missing values, which will form a posterior distribution for what this value might have been.
In a (partially-specified, for brevity) linear model, this might look as follows:
where \(N_i\) is our sometimes-missing predictor. When \(N_i\) is observed, \(\mathcal{N}(\nu, \sigma_N)\) serves as a likelihood: given this data-point, we tweak retrodictive distributions on the parameters \((\nu, \sigma_N)\) by which it was produced. Conversely, when \(N_i\) is missing it serves as a prior: after learning distributions of \((\nu, \sigma_N)\) we can generate a likely value of \(N_i\) itself. Finally, inference will give us (presumably-wide) distributions on the model's belief in what was the true value of each missing \(N_i\) conditional on the data observed.
I tried this in Edward, albeit briefly, to no avail. Dustin Tran gives an example of how one might accomplish this task in the case of Gaussian Matrix Factorization. In my case, I wasn't able to apply a 2-D missing-data-mask placeholder to a 2-D data placeholder via tf.gather nor tf.gather_nd. With more effort, I'm sure I could make this work. Help appreciated.
For now, we'll first drop columns containing too many null values, then, after choosing a few of the predictors most correlated with the target, drop the remaining rows containing nulls.
Select three fixed-effect predictors
fixed_effect_predictors = [
'area_live_finished',
'num_bathroom',
'build_year'
]
Select one random-effect predictor
zip_codes = data['region_zip'].astype('category').cat.codes
Split data into train, validation sets
Dataset sizes:
X_train: (36986, 3)
X_val: (36986, 3)
y_train: (36986,)
y_val: (36986,)
Bayesian linear regression
Using three fixed-effect predictors we'll fit a model of the following form:
Having normalized our data to have mean 0 and unit-variance, we place our priors on a similar scale.
To infer posterior distributions of the model's parameters conditional on the data observed we employ variational inference — one of three inference classes supported in Edward. This approach posits posterior inference as posterior approximation via optimization, where optimization is done via stochastic, gradient-based methods. This is what enables us to scale complex probabilistic functional forms to large-scale data.
For an introduction to variational inference and Edward's API thereof, please reference:
- Edward: Inference of Probabilistic Models
- Edward: Variational Inference
- Edward: KL(q||p) Minimization
- Edward: API and Documentation - Inference
Additionally, I provide an introduction to the basic math behind variational inference and the ELBO in the previous post on this blog: Further Exploring Common Probabilistic Models.
Fit model
For the approximate q-distributions, we apply the softplus function — log(exp(z) + 1) — to the scale parameter values at the suggestion of the Edward docs.
N, D = X_train.shape
# fixed-effects placeholders
fixed_effects = tf.placeholder(tf.float32, [N, D])
# fixed-effects parameters
β_fixed_effects = Normal(loc=tf.zeros(D), scale=tf.ones(D))
α = Normal(loc=tf.zeros(1), scale=tf.ones(1))
# model
μ_y = α + ed.dot(fixed_effects, β_fixed_effects)
y = Normal(loc=μ_y, scale=tf.ones(N))
# approximate fixed-effects distributions
qβ_fixed_effects = Normal(
loc=tf.Variable(tf.random_normal([D])),
scale=tf.nn.softplus(tf.Variable(tf.random_normal([D])))
)
qα = Normal(
loc=tf.Variable(tf.random_normal([1])),
scale=tf.nn.softplus(tf.Variable(tf.random_normal([1])))
)
Infer parameters
latent_vars = {
β_fixed_effects: qβ_fixed_effects,
α: qα
}
sess.run(INIT_OP)
inference = ed.KLqp(latent_vars, data={fixed_effects: X_train, y: y_train})
inference.run(n_samples=5, n_iter=250)
250/250 [100%] ██████████████████████████████ Elapsed: 4s | Loss: 35405.105
Criticize model
Visualize data fit given parameter priors
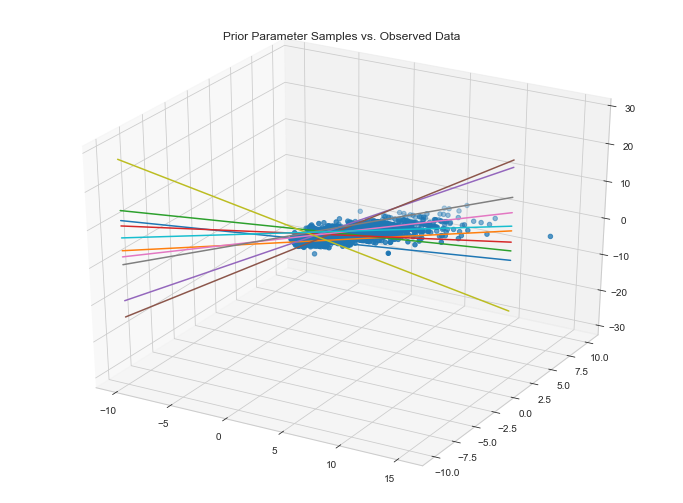
Visualize data fit given parameter posteriors
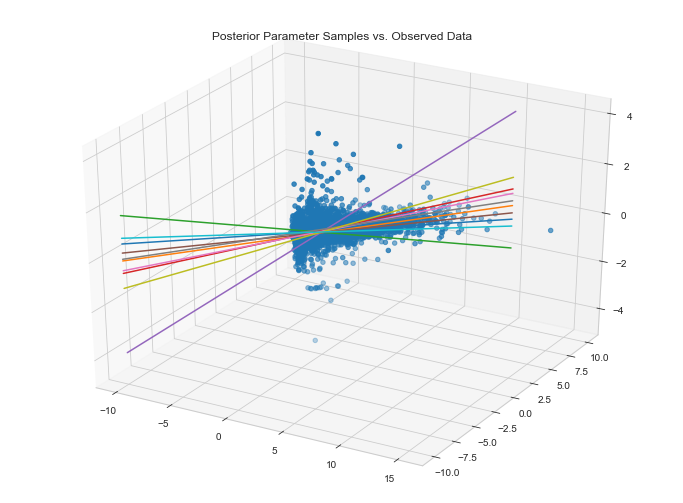
It appears as if our model fits the data along the first two dimensions. This said, we could improve this fit considerably. This will become apparent when we compute the MAE on our validation set.
param_posteriors = {
β_fixed_effects: qβ_fixed_effects.mean(),
α: qα.mean()
}
X_val_feed_dict = {
fixed_effects: X_val
}
y_posterior = ed.copy(y, param_posteriors)
print(f'Mean validation `logerror`: {y_val.mean()}')
compute_mean_absolute_error(y_posterior, X_val_feed_dict)
Mean validation `logerror`: 0.012986094738549725
Mean absolute error on validation data: 0.089943
Inspect residuals
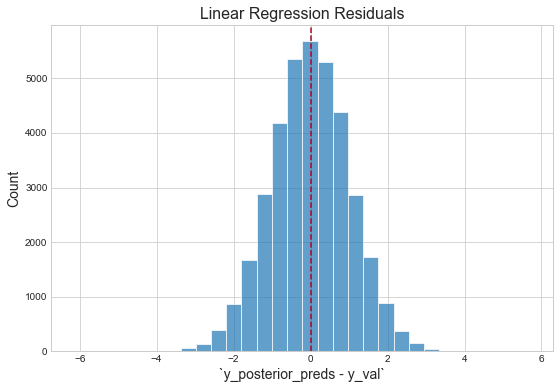
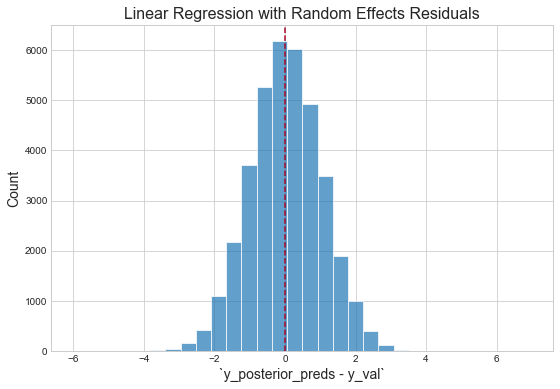
"The residuals appear normally distributed with mean 0: this is a good sanity check for the model."1 However, with respect to the magnitude of the mean of the validation logerror, our validation score is terrible. This is likely due to the fact that three predictors are not nearly sufficient for capturing the variation in the response. (Additionally, because the response itself is an error, it should be fundamentally harder to capture than the thing actually being predicted — the house price. This is because Zillow's team has already built models to capture this signal, then effectively threw the remaining "uncaptured" signal into this competition, i.e. "figure out how to get right the little that we got wrong.")
Inspect parameter posteriors
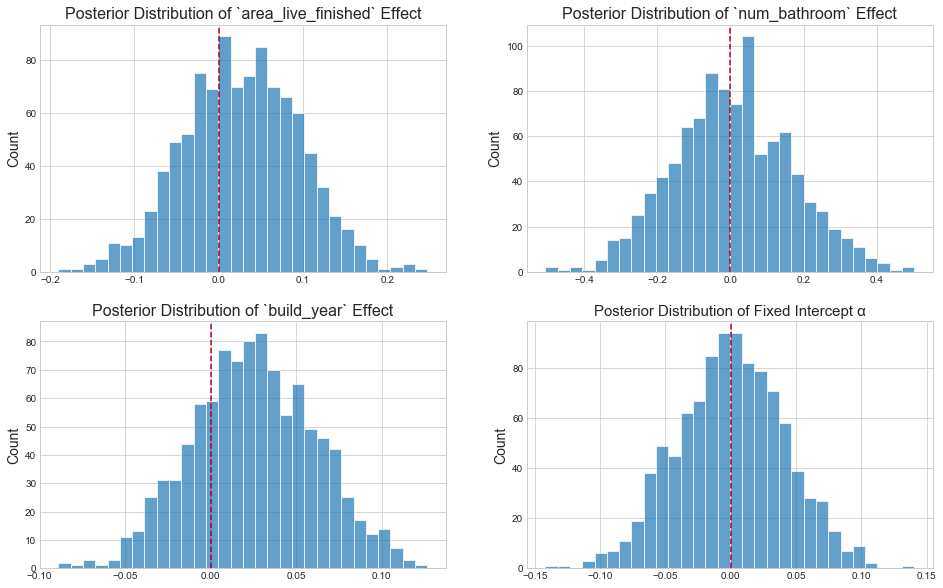
In keeping with the definition of multivariate linear regression itself, the above parameter posteriors tell us: "conditional on the assumption that the log-error and fixed effects can be related by a straight line, what is the predictive value of one variable once I already know the values of all other variables?"2
Bayesian linear regression with random effects
Random effects models — also known as hierarchical models — allow us to ascribe distinct behaviors to different "clusters" of observations, i.e. groups that may each act in a materially unique way. Furthermore, these models allow us to infer these tendencies in a collaborative fashion: while each cluster is assumed to behave differently, it can learn its parameters by heeding to the behavior of the population at large. In this example, we assume that houses in different zipcodes — holding all other predictors constant — should be priced in different ways.
For clarity, let's consider the two surrounding extremes:
- Estimate a single set of parameters for the population, i.e. the vanilla, scikit-learn linear regression, Bayesian or not. This confers no distinct behaviors to houses in different zipcodes.
- Estimate a set of parameters for each individual zipcode, i.e. split the data into its cluster groups and estimate a single model for each. This confers maximally distinct behaviors to houses in different zip codes: the behavior of one cluster knows nothing about that of the others.
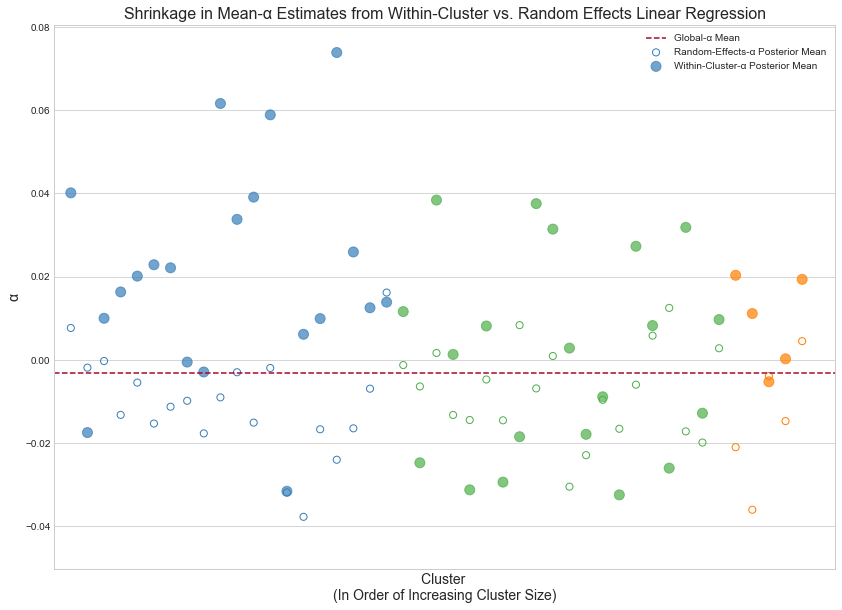
Random-effects models "walk the line" between these two approaches — between maximally underfitting and maximally overfitting the behavior of each cluster. To this effect, its parameter estimates exhibit the canonical "shrinkage" phenomenon: the estimate for a given parameter is balanced between the within-cluster expectation and the global expectation. Smaller clusters exhibit larger shrinkage; larger clusters, i.e. those for which we've observed more data, are more bullheaded (in typical Bayesian fashion). A later plot illustrates this point.
We specify our random-effects functional form as follows:
μ_y = α + α_random_effects + ed.dot(fixed_effects, β_fixed_effects)
y = Normal(loc=μ_y, scale=tf.ones(N))
With respect to the previous model, we've simply added α_random_effects to the mean of our response. As such, this is a varying-intercepts model: the intercept term will be different for each cluster. To this end, we learn the global intercept α as well as the offsets from this intercept α_random_effects — a random variable with as many dimensions as there are zipcodes. In keeping with the notion of "offset," we ascribe it a prior of (0, σ_zc). This approach allows us to flexibly extend the model to include more random effects, e.g. city, architecture style, etc. With only one, however, we could have equivalently included the global intercept inside of our prior, i.e. α_random_effects ~ Normal(α, σ_zc), with priors on both α and σ_zc as per usual. This way, our random effect would no longer be a zip-code-specific offset from the global intercept, but a vector of zip-code-specific intercepts outright.
Finally, as Richard McElreath notes, "we can think of the σ_zc parameter for each cluster as a crude measure of that cluster's "relevance" in explaining variation in the response variable."3
Fit model
n_zip_codes = len(set(zip_codes))
# random-effect placeholder
zip_codes_ph = tf.placeholder(tf.int32, [N])
# random-effect parameter
σ_zip_code = tf.sqrt(tf.exp(tf.Variable(tf.random_normal([]))))
α_zip_code = Normal(loc=tf.zeros(n_zip_codes), scale=σ_zip_code * tf.ones(n_zip_codes))
# model
α_random_effects = tf.gather(α_zip_code, zip_codes_ph)
μ_y = α + α_random_effects + ed.dot(fixed_effects, β_fixed_effects)
y = Normal(loc=μ_y, scale=tf.ones(N))
# approximate random-effect distribution
qα_zip_code = Normal(
loc=tf.Variable(tf.random_normal([n_zip_codes])),
scale=tf.nn.softplus(tf.Variable(tf.random_normal([n_zip_codes])))
)
Infer parameters
latent_vars = {
β_fixed_effects: qβ_fixed_effects,
α: qα,
α_zip_code: qα_zip_code
}
sess.run(INIT_OP)
inference = ed.KLqp(latent_vars, data={fixed_effects: X_train, zip_codes_ph: zip_codes[train_index], y: y_train})
inference.run(n_samples=5, n_iter=250)
250/250 [100%] ██████████████████████████████ Elapsed: 6s | Loss: 34898.613
Criticize model
Mean absolute error on validation data: 0.084635
Inspect residuals
Plot shrinkage
To illustrate shrinkage we'll pare our model down to intercepts only (removing the fixed effects entirely). We'll first fit a random-effects model on the full dataset then compute the cluster-specific-intercept posterior means. Next, we'll fit a separate model to each individual cluster and compute the intercept posterior mean of each. The plot below shows how estimates from the former can be viewed as "estimates from the latter — shrunk towards the global-intercept posterior mean."
Finally, blue, green and orange points represent small, medium and large clusters respectively. As mentioned before, the larger the cluster size, i.e. the more data points we've observed belonging to a given cluster, the less prone it is to shrinkage towards the mean.
Neural network with random effects
Neural networks are powerful function approximators. Keras is a library that lets us flexibly define complex neural architectures. Thus far, we've been approximating the relationship between our fixed effects and response variable with a simple dot product; can we leverage Keras to make this relationship more expressive? Is it painless? Finally, how does it integrate with Edward's existing APIs and constructs? Can we couple nimble generative models with deep neural networks?
While my experimentation was brief, all answers point delightfully towards "yes" for two simple reasons:
- Edward and Keras both run on TensorFlow.
- "Black-box" variational inference makes everything scale.
This said, we must be nonetheless explicit about what's "Bayesian" and what's not, i.e. for which parameters do we infer full (approximate) posterior distributions, and for which do we infer point estimates of the posterior distribution.
Below, we drop a neural_network in place of our dot product. Our latent variables remain β_fixed_effects, α and α_zip_code: while we will infer their full (approximate) posterior distributions as before, we'll only compute point estimates for the parameters of the neural network as in the typical case. Conversely, to the best of my knowledge, to infer full distributions for the latter, we'll need to specify our network manually in raw TensorFlow, i.e. ditch Keras entirely. We then treat our weights and biases as standard latent variables and infer their approximate posteriors via variational inference. Edward's documentation contains a straightforward tutorial to this end.
Fit model
def neural_network(fixed_effects, λ=.001, input_dim=D):
dense = Dense(5, activation='tanh', kernel_regularizer=l2(λ))(fixed_effects)
output = Dense(1, activation='linear', name='output', kernel_regularizer=l2(λ))(dense)
return K.squeeze(output, axis=1)
# model
fixed_effects = tf.placeholder(tf.float32, [N, D])
μ_y = α + α_random_effects + neural_network(fixed_effects)
y = Normal(loc=μ_y, scale=tf.ones(N))
latent_vars = {
β_fixed_effects: qβ_fixed_effects,
α: qα,
α_zip_code: qα_zip_code
}
sess.run(INIT_OP)
inference = ed.KLqp(latent_vars, data={fixed_effects: X_train, zip_codes_ph: zip_codes[train_index], y: y_train})
optimizer = tf.train.RMSPropOptimizer(0.01, epsilon=1.0)
inference.initialize(optimizer=optimizer)
inference.run(n_samples=5, n_iter=1000)
1000/1000 [100%] ██████████████████████████████ Elapsed: 18s | Loss: 34446.191
Criticize model
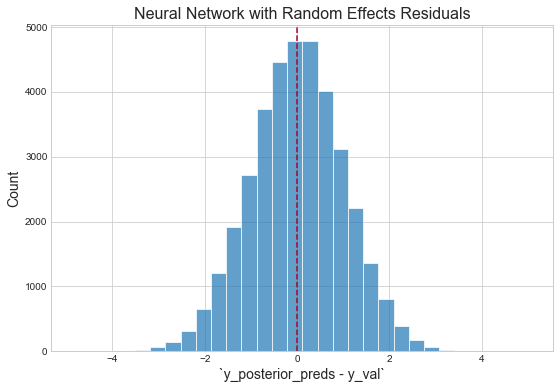
Mean absolute error on validation data: 0.081484
Inspect residuals
Future work
We've now laid a stable, if trivially simple foundation for building models with Edward and Keras. From here, I see two distinct paths to building more expressive probabilistic models using these tools:
- Build probabilistic models in Edward, and abstract deep-network-like subgraphs into Keras layers. This allows us to flexibly define complex neural architectures, e.g. a video question answering model, with a nominal amount of code, yet restricts us from, or at least makes it awkward to, infer full posterior distributions for the subgraph parameters.
- Build probabilistic models in Edward, and specify deep-network-like subgraphs with raw TensorFlow — ditching Keras entirely. Defining deep-network-like subgraphs becomes more cumbersome, while inferring full posterior distributions for the subgraph parameters becomes more natural and consistent with the flow of Edward code.
This work has shown a few basic variants of (generalized) Bayesian linear regression models. From here, there's tons more to explore — varying-slopes models, Gaussian process regression, mixture models and probabilistic matrix factorizations to name a random few.
Edward and Keras have proven a flexible, expressive and powerful duo for performing inference in deep probabilistic models. The models we built were simple; the only direction to go, and to go rather painlessly, is more.
Many thanks for reading.
Code
The repository and rendered notebook for this project can be found at their respective links.
References
- Edward - Linear Mixed Effects Models
- McElreath, Richard. "Chapter 5." Statistical Rethinking: A Bayesian Course with Examples in R and Stan. Boca Raton, FL: CRC, Taylor & Francis Group, 2016. N. pag. Print.
- McElreath, Richard. "Chapter 12." Statistical Rethinking: A Bayesian Course with Examples in R and Stan. Boca Raton, FL: CRC, Taylor & Francis Group, 2016. N. pag. Print.
- The Best Of Both Worlds: Hierarchical Linear Regression in PyMC3
- Keras as a simplified interface to TensorFlow
- Mixture Density Networks with Edward, Keras and TensorFlow
- Use a Hierarchical Model
- McElreath, Richard. "Chapter 14." Statistical Rethinking: A Bayesian Course with Examples in R and Stan. Boca Raton, FL: CRC, Taylor & Francis Group, 2016. N. pag. Print.